Dies ist ein Gastartikel von Pingpong
Da es zum Thema künstliche Intelligenz immer wieder viele Fragen, Diskussionen und Bedenken gibt, sollen in diesem Artikel die Grundlagen erklärt werden: Wie genau funktioniert das eigentlich, wenn Maschinen lernen? Dazu schauen wir uns die künstlichen neuronalen Netze geenauer an. Diese sind der Motor hinter den großen Sprachmodellen, den Bildgeneratoren, der automatischen Übersetzung und dem ganzen KI-Hype der letzten Jahre. Ich versuche die ganze Sache möglichst simpel und intuitiv zu halten, es soll ein 101, also ein einfacher Einstieg in das Thema sein.
Da Künstliche Intelligenz stark auf Mathematik aufbaut, wird dabei notgedrungen auch etwas Mathematik vorkommen. Das beschränkt sich jedoch auf Oberstufenmathematik – mehr braucht es nicht, um den Computer lernen zu lassen!
1. Funktionen und Parameter
Als Beispiel nehme ich die Polynomfunktionen zweiten Grades, also die bekannten quadratischen Funktionen, die jeder aus der Schule kennt. Diese Funktionen haben die Form f(x)=ax2+bx+c wobei a,b,c die Parameter der Funktion sind. Man kann sich das ganze als Box vorstellen, mit Einstellknöpfen für die Parameter.

In Schule sind die Parameter meist fix vorgegeben. Man arbeitet mit einer konkreten Funktion, z.B. für a=2, b=-1.3 und c=3.4 ist es die Funktion f(x)=2x2−1.3x+3.4. Dann kann man für verschiedene Werte von x den Funktionswert f(x) bestimmen und allerhand Analysis mit dieser Funktion betreiben.
Bei neuronalen Netzen hat man einen etwas anderen Blick auf die Funktionen. Anstatt die Parameter zu fixieren und x zu variieren, ist es bei den neuronalen Netzen in einem gewissen Sinn gerade umgekehrt: Der input x ist vorgegeben, und man interessiert sich dafür, wie sich die Funktion verhält, wenn man die Parameter variiert. Ich habe zu diesem Zweck eine interaktive Visualisierung erstellt, wo man das ausprobieren kann: https://claude.ai/public/artifacts/1c3efa8e-7e8c-42ce-b422-08b43815a5c4
Am besten öffnet man die Visualisierung in einem neuen tab, sodass man zwischen dem Artikel und der Visualisierung hin und her schalten kann. In der Visualisierung gibt es drei Schieberegler, mit denen man die Parameter a,b,c ändern kann. Unterhalb sieht man jeweils, wie sich die Funktion sowie deren Graphen ändert.
Beim Lernen mit neuronalen Netzen dreht sich alles um folgende zentrale Fragestellung: Wie muss ich die Regler für die Parameter einstellen, damit die Funktion das tut was ich möchte? Der Umstand, dass die Parameter eine wichtige Rolle spielen, ist auch in der Notation abgebildet. Die Parameter sind ein Teil des input, daher schreibt man explizit f(x,[a,b,c]). In Worten: „Eine Funktion f mit den inputs x (Variable) und [a,b,c] (Parameter)“. Und weil Mathematiker faul sind und gerne Schreibarbeit sparen, fasst man a,b,c zu einem dreidimensionalen Parametervektor p=[a,b,c] zusammen und schreibt: f(x,p). Wichtig ist hier, sich die Dinge im Kopf zu behalten: x ist ein einzelner skalarer Wert, aber p ist ein dreidimensionaler Vektor (In der Schulmathematik hat man wie gesagt meist fixe Parameter, daher spart man sich diese explizite Notation und schreibt nur f(x)).
1.1 Beispiel
Im folgenden wird als einfaches Motivationsbeispiel ein kleines machine learning Problem aufgesetzt. Zunächst müssen wir klären, wie „was ich möchte“ spezifiziert wird. Im machine learning wird das durch Trainigsdaten gemacht. Anstatt der Funktion Regeln vorzugeben, gibt man ihr Beispiele. Die Beispiele haben die Form: Wenn ich diesen Wert (x) in die Funktion reinstecke, möchte ich, dass jener Wert (f(x)=y) herauskommt.
In der interaktiven Visualisierung kann man 6 custom points eingeben. Diese werden dann als rote Kreuze in der Visualisierung dargestellt. Diese Input-Output Paare (x- und y Koordinate) sind die Trainingsdaten, sie legen das gewünschte Verhalten der Funktion fest.

Die 6 input-Werte sind: 1.6, -2.3, -1.1, 0, 3.5, 4.3
Die 6 output-Werte sind: -5.3, -41.8, -27.1, -14.3, -3, -4.3
Die Aufgabe lautet: Passe mit den Schiebereglern die Parameter der quadratischen Funktion an, sodass der Funktionsgraph möglichst genau auf den roten Kreuzen liegt. Es lohnt sich, ein bisschen mit der Visualisierung herumzuspielen und zu versuchen die Aufgabe zu lösen, bevor man weiterliest.
ACHTUNG SPOILER: Eine mögliche Lösung lautet a=-1.3, b=7.9 und c=-14.7
Nun kann man einwenden, ok, ich habe mit der Hand probiert bis es passt, was ist da jetzt dabei? Die ganze Magie der neuronalen Netze besteht darin, dass es eine automatische Methode, d.h. einen Algorithmus, gibt, der genau das macht. Wenn man nochmal auf das erste Bild von der Funktion als Box mit Drehreglern zurückkommt, dann gibt es quasi ein Orakel, das so lange an den Reglern dreht, bis die Funktion das gewünschte Verhalten hat. Es ist wie Zauberei!
2. Optimierung
Der spannende Punkt ist, wie genau dieser Algorithmus funktioniert. Um das zu verstehen braucht man ein paar Grundlagen aus der mathematischen Optimierung. Bei der Optimierung geht es darum, das Minimum (oder Maximum) einer Funktion zu finden. Formal notiert man ein Optimierungsproblem als minxf(x). In Worten: finde jenen Wert x, sodass der Funktionswert f(x) so klein wie möglich (minimal) ist.
Vorhin bestand das Ziel darin, mit den Reglern zu spielen sodass der Funktionsgraph auf den roten Kreuzen liegt. Um das zu automatisieren, muss man das Ziel in die Sprache der Mathematik übersetzen. Das funktioniert folgendermaßen: Man weiß zu jedem input-Wert xi welchen output-Wert yi man haben möchte. Der Index i nummeriert die einzelnen Trainingspaare, damit wir nicht durcheinander kommen. Das erste Trainigspaar ist beispielsweise x1=1.6, y1=−5.3.
Am Anfang, wenn man die „richtigen“ Parameter p nicht kennt, wird der Funktionswert f(xi,p) für einen gegebenen input-Wert xi natürlich überhaupt nicht dem genwünschten output-Wert yi entsprechen. Man stellt also den quadratischen Fehler zwischen dem Funktionswert f(xi,p) und dem gewünschten Ergebnis auf:
E(xi,yi,p)=(f(xi,p)−yi)2.
Der Fehler ist selber eine Funktion, ich nenne sie E (von engl. error), und sie hat 3 inputs: Das jeweilige Input-Output-Paar xi,yi und die Parameter p. Im folgenden wird es dann darum gehen, diesen Fehler zu minimieren.
Den Fehler für das erste Input-Output-Paar x1,y1 und die Parameter p=[1,0,0] rechnet man zB so aus: p enthält ja die Parameter a,b,c und für a=1, b=0, c=0 erhält man die kanonische Quadratfunktion f(x,p)=x2. Damit berechnet man: f(1.6,p)=1.62=2.56
(Wir benutzen weiterhin die Notation f(x,p), obwohl wir eine konkrete Parameterkonfiguration betrachten. Das soll explizit machen, dass es sich bei den Parametern prinzipiell um einen veränderbaren input handelt.)
Der gewünschte Wert ist aber y1=−5.3, d.h. der Fehler ist (einsetzen der Werte in die Funktion E)
E(1.6,−5.3,p)=(2.56−(−5.3))2=61.7796
Wenn man für die Parameter hingegen p=[-1,1,0] hat, ergibt das die Funktion f(x,p)=−x2+x. Der Funktionswert ist dann f(1.6,p)=−(1.62)+1.6=−0.96 und der Fehler ist
E(1.6,−5.3,p)=(−0.96−(−5.3))2=4.342=18.8356
Hier sieht man schon, wohin die Reise geht. Bei der Fehlerfunktion E sind es nicht wie üblich die Werte für x die frei variieren, sondern die Parameterwerte p. Das ist die „verkehrte“ machine learning Sichtweise, die ganz oben angesprochen wurde. In der Schule ist x die Variable, und die Parameter sind fix. Bei neuronalen Netzen hat man eine Menge an vorgebenen Trainigsdaten, und die Parameter sind variabel. Diese Sichtweise korrespondiert genau dazu, wenn man in der Visualisierung an den Reglern für a,b,c spielt und damit die Parameter ändert. Das ist einer der wesentlichen gedanklichen Schritte, den man braucht um neuronale Netze zu verstehen.
2.1 Loss-Funktion
Was jetzt noch zu tun bleibt, ist, die Fehler von allen Input-Output-Paaren aufzusummieren. Damit erhält man die sogenannte Loss-Funktion:
L(X,Y,p)=∑iE(xi,yi,p)=∑i(f(xi,p)−yi)2
Hier bezeichnet X,Y die Menger alle Input-Output-Paare xi,yi. Die Loss-Funktion sagt, wie groß der Fehler über alle Input-Output-Paare für eine bestimmte Konfiguration der Parameter p ist. Um deutlich zu machen, dass die Parameter der variable input sind, ordnet man die inputs um und notiert
L(p,X,Y)
sodass die Variable wie gewohnt an erster Stelle steht.
(Oft macht man auch diesselbe – diesmal aber umgekehrt! – Vereinfachung wie in der Schule: da die Trainingsdaten fix vorgegeben sind lässt man die X,Y weg und schreibt einfach nur L(p)).
Nun kann man das Optimierungsproblem aufstellen:
minpL(p,X,Y)
In Worten: Finde die Parameter p, sodass der Wert der Loss-Funktion mit den Trainigsdaten X,Y minimal ist. Da die Loss-Funktion die Summe aller Abweichungen der Funktionswerte f(xi,p) zu den gewünschten Werten yi ist, entspricht dieses Problem genau dem, was man händisch in der Visualisierung machen kann: An den Parametern drehen, bis der Funktionsgraph möglichst gut auf den roten Kreuzen liegt.
2.2 Gradientenabstieg
Im Kontext neuronale Netze wird das Optimierungsproblem üblicherweise mit einer Variante von Gradientenabstieg (engl. gradient descent) gelöst. Der Gradientenabstieg ist DAS Arbeitspferd hinter der ganzen KI, sämtliche großen neuronalen Netze verwenden das in der einen oder anderen Form.
Die Grundidee von gradient descent ist sehr einfach: Angenommen man hat eine Funktion f(x) die man minimieren möchte, und einen Punkt x an dem man gerade ist (Achtung, hier haben wir wieder die übliche Sichtweise, wo x die Variable ist! Man benötigt oft eine gewisse Flexibilität, da je nach Kontext die eine oder andere Sichtweise verwendet wird…). Dann möchte man wissen, in welche Richtung muss man sich bewegen, d.h. muss x kleiner oder größer werden, damit sich der Funktionswert verringert – man möchte ja das Minimum der Funktion finden. Jetzt gibt es ein Orakel, welches einem sagt in welche Richtung man gehen muss. Dann geht man ein Stück in diese Richtung, d.h. man steht an einem neuen Punkt x. Nun fragt man wieder das Orakel, macht wieder einen Schritt in diejenige Richtung wo der Funktionswert sich verringert, und immer so weiter bis man das Minimum erreicht hat.
Das Orakel ist der Gradient. Aus der Kurvendiskussion in der Schule kennt man vielleicht noch die Ableitung f′(x). Der Gradient ist im Prinzip dasselbe wie die Ableitung. Nur sagt man im mehrdimensionalen zur Ableitung Gradient, und statt f′(x) notiert man ∇f(x) (gesprochen: Nabla f). Ebenfalls aus der Kurvendiskussion kann man sich eventuell erinnern, dass die Ableitung die Änderungsrate der Funktion ist. Das ist genau das, was man braucht: Die Ableitung (Gradient) sagt einem, wie sich der Funktionswert ändert, wenn man x ändert. Und wenn man weiß, wie sich der Funktionswert ändert, dann weiß man in welche Richtung man gehen muss damit der Funktionswert kleiner wird.
Beispiel
Angenommen man hat eine einfache Funktion, zB f(x)=3x2−2.3x+1.7. Die Ableitung für die Funktion kann man leicht ausrechnen:
f′(x)=6x−2.3
Wenn die Ableitung in einem Punkt positiv x ist, bedeutet das der Funktionswert wächst, wenn man x größer macht. Sagen wir, wir sind im Punkt x=3.1. Die Ableitung an diesem Punkt ist f′(3.1)=6⋅3.1−2.3=16.3. Der Wert ist positiv, d.h. an diesem Punkt gilt: Wenn man x größer macht, wird f(x) ebenfalls größer.
Neue Situation, wir sind jetzt in einem anderen Punkt x=−1.1. Die Ableitung an diesem Punkt ist f′(−1.1)=−8.9. Der Wert ist negativ, d.h. an diesem Punkt gilt: Wenn man x kleiner macht, wird f(x) größer.
Allgemein sagt der Gradient an einem Punkt x, in welche Richtung die Funktion am stärksten wächst. Wenn man also das Minimum der Funktion sucht, dann braucht man nur ein Stück in die entgegengesetzte Richtung zu gehen. Das ist das Grundprinzip des Gradientenabstieg.
2.2.1 Gradientenabstieg auf der Loss-Funktion
Wir widmen uns wieder der Loss-Funktion aus Abschnitt 2.2 (Achtung, jetzt sind die Parameter p wieder die Variable!). Im Prinzip funktioniert die Optimierung der Loss-Funktion genau so, wie vorhin beschrieben. Man muss die Loss-Funktion ableiten, und zwar nach den Parametern. Und da es 3 Parameter gibt, ist das Ergebnis (der Gradient) ein dreidimensionaler Vektor. Diese Ableitungen funktionieren so, wie man es aus der Schule kennt: Wenn man beispielsweise nach dem Parameter a ableitet, betrachtet man die restlichen Variablen als konstant. Dasselbe Spiel macht man dann für die Parameter b und c. Da die Loss-Funktion eine verkettete Funktion ist und sich die Parameter ganz „innen“ befinden, muss man für die Berechnung der Ableitung die Kettenregel anwenden (Den Gradient selber ausrechnen ist als Übung sehr empfehlenswert!).
Ich habe hier alles in einem kleinen python notebook implementiert: https://colab.research.google.com/github/pingpong402/networks101/blob/main/simple_quadratic.ipynb
Man kann das notebook starten, indem man links oben auf den Play-Button drückt Dazu muss man mit seinem google Konto angemeldet sein, damit man das script in sein eigenes Colab kopieren kann. Wer das nicht möchte kann auch eine anonyme virtuelle Maschine starten, indem man auf den „launch binder“ button klickt. Dazu ist keine Anmeldung notwendig. Nach einer kurzen Wartezeit erhält man eine interaktive Jupyter Notebook Umgebung, in der das script geladen ist. Man kann es dann oben in der Menüleiste mit dem Play Button starten.
Das script führt Gradientenabstieg auf der Loss-Funktion aus, um die optimalen Parameter zu lernen. Es verwendet kein machine learning Framework, alles ist hier wirklich mit der Hand gemacht. Für das kleine Beispiel geht das sehr einfach: es sind weniger als 40 Zeilen Code, und das eigentliche „Lernen“ (die Optimierung) sind weniger als 5 Zeilen. Man erhält als Ergebnis die gelernten Parameter, sowie eine Visualisierung wie sich der Loss während der Optimierung entwickelt und wie die Funktion mit den gelernten Parametern aussieht:

Am Anfang startet man mit initialen Parametern p=[1,0,0]. Die entsprechende Funktion passt überhaupt nicht zu den Trainingsdaten, und der Loss ist groß. Nach der Optimierung hat der Algorithmus folgende Parameter gefunden: p=[-1.4, 8.5, -15.1]. Der Loss ist sehr klein, und die entsprechende Funktion liegt ziemlich genau auf den Trainingsdaten. Glückwunsch, hiermit hat man ein echtes machine learning Beispiel durchexerziert!(Wie gut passen die Parameter, die man beim händischen Probieren gefunden hat, zu den Parametern die der Algorithmus findet?)
Man kann in dem script herumspielen, z.B. die initialen Parameter ändern, oder die Anzahl der Iterationen für den Gradientenabstieg. Fortgeschrittene können auch andere Trainigsdaten definieren und eine neue Funktion lernen (Aber Vorsicht, da hier lediglich mit einer quadratischen Funktion gearbeitet wird kann nicht jede Konfiguration von Trainingsdaten gelernt werden!).
3. Modellierung von Neuronalen Netzwerken
Nun ist dieses kleine Beispiel ganz nett, es hat aber zugegeben wenig mit den beeindruckenden Ergebnissen der großen KI-Systeme zu tun. Das liegt im wesentlichen daran, dass in dem kleinen Beispiel die Funktion f – eine quadratische Funktion – nur geringe deskriptive Kraft hat. Sie hat lediglich 3 Parameter, und damit kann man nur eine kleine Klasse von Funktionen abdecken. Entsprechend sind die Probleme, die man damit lösen kann, recht eingeschränkt. Interessanter wird die ganze Sache, wenn man Funktionen mit viel mehr Parametern verwendet. Dabei nimmt man aber nicht einfach Polynomfunktionen höherer Ordnung, z.B. eine Polynomfunktion vom Grad 100. Man verwendet stattdessen eine ganz andere Struktur bzw Architektur.
Eine der bekanntesten und meist verwendeten Architekturen ist das Multilayer Perzeptron (MLP). Das MLP ist tatsächlich dem Gehirn nachempfunden. Es besteht aus einer Reihe von Einheiten (Neuronen), wobei jedes Neuron mehrere inputs hat und diese mit einer einfachen Funktion in einen Output transformiert. Jedes Neuron ist im Prinzip genau dasselbe wie die mathematische Box von ganz zu Beginn. Es gibt Inputs, Drehregler für die Parameter, und einen Output. Nur verwendet man keine Polynomfunktionen, sondern die Funktion der Neuronen hat folgende Struktur:
f(x)=φ(∑iaixi+b), x=[x1,x2,…,xi]∈Rn
Diese Funktion besteht aus zwei Teilen: „innen“ wird eine einfache lineare Transformation berechnet (gewichtete Summe und Konstante), mit den Parametern a,b. Auf dieses Ergebnis wird dann eine nichtlineare Aktivierungsfunktion φ(⋅) angewandt. Für diese nichtlineare Funktion gibt es einige weitverbreitete Möglichkeiten, beispielsweise die logistische Funktion, die tanh Funktion oder die ReLu (rectified linear unit) Funktion. Diese Funktionen sind im folgenden abgebildet:

(Die Bezeichnung Aktivierungsfunktion bezieht sich auf die Parallele zur Funktionsweise von echten Neuronen, die ab einem bestimmten input-Schwellwert aktiviert werden und feuern.)Die Aktivierungsfunktionen sind zwar relativ einfache Funktionen, spielen aber eine wichtige Rolle. Echte neuronale Netzwerke bestehen i.d.R. aus mehreren hintereinander geschalteten Layern von Neuronen. Man kann zeigen, dass sich alle diese Layer auf einen einzigen Layer reduzieren lassen, wenn man keine nichtlinearen Aktivierungsfunktionen verwendet. Erst durch die Aktivierungsfunktion wird das neuronale Netzwerk tatsächlich „mächtiger“, wenn man mehr Layer hintereinander schaltet.
Ein weiterer wesentlicher Unterschied von „richtigen“ neuronalen Netzen zu dem kleinen machine learning Beispiel von vorhin besteht darin, dass in dem kleinen Beispiel der Input und der Output jeweils eine Zahl, d.h. ein skalarer Wert war. Bei neuronalen Netzen arbeitet man hingegen mit mehrdimensionale Vektoren. D.h. der input x ist ein Vektor, und xi bezeichnet die Komponenten dieses Vektors. Die Anzahl der Parameter für die gesamte Funktion f eines einzelnen Neuron hängt demnach von der Dimension d des Input ab: Ein Neuron hat d+1 Parameter. d Parameter für die ai (ein ai für jede Komponente des input Vektors) und ein zusätzlicher für das b. Die Aktivierungsfunktion hat keine Parameter. Man beachte hier, dass der Input eines Neuron ein Vektor ist, der Output ist jedoch ein skalarer Wert, eine einzelne Zahl.
Die einfachste Version des MLP ist dreilagig und besteht aus einem input Layer, einem sogenannten hidden Layer mit einer frei wählbaren Anzahl von Neuronen, und einem output Layer. Die Anzahl der Einheiten im input und output Layer richtet sich nach dem konkreten Anwendungsfall. Eine schematische Darstellung eines MLP mit 3 Einheiten im input Layer, 3 Einheiten im hidden layer, und 2 Einheiten im output Layer sieht zB folgendermaßen aus:

Jede der Einheiten ist eine Funktion wie oben beschrieben (lineare Transfomration und nichtlineare Aktivierungsfunktion), man stellt es sich am besten mit dem Bild von ganz zu Beginn vor: eine mathematische Box mit inputs, outputs, und Drehreglern für die Parameter. Die Pfeile geben an, wie die inputs und outputs der einzelnen Boxen miteinander verbunden sind.
Man kann dieses Bild der mathematischen Box auf verschiedenen Ebenen anwenden. Beispielsweise kann man sich auch den ganzen hidden Layer als eine Box vorstellen (mit einer Anzahl von kleineren Boxen im Inneren). Und man kann sich das ganze Netzwerk als eine große Box vorstellen, die im Inneren aus mehreren Layern besteht, die selbst wiederum aus den einzelnen Neuronen bestehen. Es ist immer dasselbe allgemeine Prinzip: Es gibt inputs, outputs, und Drehregler für Parameter. Wenn man sich das ganze Netzwerk als eine große Box vorstellt, dann hat diese natürlich sehr viel mehr Drehregler als eine der kleineren Boxen im Inneren.
Der große Erfolg der neuronalen Netze beruht darauf, dass diese Architektur sehr flexibel ist. Gleichzeitig hat sich herausgestellt, dass die resultierende Gesamtfunktion (also die große Box, wo man das ganze Netzwerk als eine Funktion betrachtet) ungeheuer ausdrucksstark ist, und man eine ganze Menge interessante Probleme damit lösen kann. Tatsächlich kann man zeigen, dass ein MLP mit einem hidden layer und nichtlinearen Aktivierungsfunktionen eine universelle Approximationseigenschaft besitzt: Man kann damit jede(!) stetige Funktion beliebig genau darstellen. (Der Pferdefuß an solchen theoretischen Beweisen ist die Kluft zur Praxis: Man braucht dafür u.U. unendlich viele Enheiten im hidden Layer…)
3.1 Einfaches Beispiel mit MLP
Wir können das einfache Beispiel mit den 6 Punkten mit dem MLP lernen. Die Loss Funktion ist nach wie vor die Summe der Fehler über alle Trainingsbeispiele:
L(X,Y,p)=∑iE(xi,yi,p)=∑i(f(xi,p)−yi)2
Nur ist jetzt die Funktion f nicht mehr ein einfaches Polynom zweiten Grades, sondern es ist die Gesamtfunktion des MLP. Das MLP sieht folgendermaßen aus:

Da wir eine einzelne Zahl als input und output haben, gibt es jeweils eine Einheit im input bzw. output Layer. Der hidden Layer hat eine frei wählbare Anzahl von Einheiten, in diesem Fall verwenden wir zwei. Für dieses einfache MLP kann man die Gesamtfunktion explizit aufschreiben. Die Funktionen im hidden layer berechnen
h1(x)=φ(a1x+b1), h2(x)=φ(a2x+b2)
und der output bzw die Gesamtfunktion f des ganzen Netzwerk lautet:
f(x,p)=a3h1(x)+a4h2(x)+b3=a3φ(a1x+b1)+a4φ(a2x+b2)+b3
mit den Parametern p=[a1,a2,a3,a4,b1,b2,b3]
Die nichtlineare Aktivierungsfunktion im output Layer lässt man weg. Diese würde den Output sonst einschränken. ZB mit der tanh Funktion wäre der Output des ganzen Netzwerk eingeschränkt auf [-1,1], und mit der ReLU Funktion wäre es beschränkt auf positive Zahlen. Die Anzahl der Parameter für jede Einheit ergibt sich nach obiger Formel d+1, mit d der Dimension des input. Der input für den hidden layer ist eindimensional, d.h. jedes Neuron hat zwei Parameter. Der input für den output Layer ist zweidimensional, d.h. das Neuron hat drei Parameter. Insgesamt hat die Funktion für das ganze MLP 7 Parameter.
Nun geht man wieder nach Schema F vor: Den Gradienten der Loss Funktion ausrechnen und Optimierung mittels Gradientenabstieg ausführen. Natürlich ist der Gradient jetzt schon ein bisschen komplizierter. Die Funktion hat 7 Parameter, d.h. der Gradient ist ein 7-dimensionaler Vektor. Für die Berechnung muss man mehrmals die Kettenregel anwenden. Der Parameter a2 ist beispielsweise „innerhalb“ der quadratischen Fehlerfunktion und nochmals „innerhalb“ der nichtlinearen Aktivierungsfunktion φ.
Die ganze Sache ist hier in einem notebook implementiert: https://colab.research.google.com/github/pingpong402/networks101/blob/main/network_quadratic.ipynb
Und das Ergebnis sieht folgendermaßen aus:

Das ist jetzt wirklich ein echtes neuronales Netzwerk dem man hier beim Lernen zuschauen kann! Und das tolle dabei, es kann im Gegensatz zu dem einfach quadratischen Polynom von vorhin tatsächlich auch andere Funktionen lernen. Man kann in dem script zusätzliche Trainigspunkte hinzufügen, dann versucht das Netzwerk eine neue Funktion zu lernen sodass der Funktionsgraph möglichst gut auf allen Punkten liegt. Hier ist beispielsweise das Ergebnis mit einem zusätzlichen Punkt [-4, 20]:

Dieses letzte Ergebnis ist immer noch mit nur 2 Neuronen im hidden layer (entspricht 7 Parametern für die Gesamtfunktion des Netzwerks). Das script ist so aufgebaut, dass man die Anzahl frei wählen kann – und natürlich wird die ganze Sache noch interessanter wenn man mehr Neuronen im hidden layer verwendet. Dadurch steigt die Ausdruckskraft des Netzwerks, und es kann die Trainingsdaten besser lernen. Hier ist das Ergebnis mit 20 Neuronen im hidden layer (entspricht 61 Parameter für das ganze Netzwerk):
 Man sieht, dass das Netzwerk hier viel besser lernen kann, nach 4000 Iterationen ist der loss bereits im Bereich 10−1, wo er vorher mit 2 Neuronen noch bei 101 lag. Am Schluss liegt die gelernte Funktion quasi perfekt auf den Trainingsdaten.
Man sieht, dass das Netzwerk hier viel besser lernen kann, nach 4000 Iterationen ist der loss bereits im Bereich 10−1, wo er vorher mit 2 Neuronen noch bei 101 lag. Am Schluss liegt die gelernte Funktion quasi perfekt auf den Trainingsdaten.
3.2 Ziffernerkennung mit MLP
Bewaffnet mit dieser Technik kann man nun daran gehen, interessante und nützliche Probleme lösen. Als abschließendes Beispiel wollen wir jetzt mit einem MLP automatisch Ziffern erkennen. Als Trainingsdaten verwenden wir den MNIST-Datensatz (das ist quasi das „hello world“ der machine learning Welt). Die Daten sehen folgendermaßen aus:

Der input ist ein 28×28 Pixel großes Bild mit handgeschriebenen Ziffern. Der output (das Label) ist die jeweilige Zahl, die auf dem Bild dargestellt ist. Insgesamt gibt es in dem Datensatz 70.000 solcher input-output Paare. Das Netzwerk soll eine Funktion lernen, die, wenn man vorne ein Bild hineinsteckt, hinten sagt welche Zahl es ist. Das ist schon ein einigermaßen schwieriges Problem. Die große Attraktivität der neuronalen Netze besteht darin, dass man sich nicht damit herumschlagen muss allerhand komplizerte Regeln zu erdenken um das Verhalten der Netzwerkfunktion (nicht vergessen, das Netzwerk ist im Grunde „nur“ eine große mathematische Funktion. Eine Box mit input, output, und Drehreglern für die Parameter) festzulegen. Man macht es genau so wie vorhin: Man gibt dem Netzwerk einfach die Trainingsbeispiele, und lässt die Parameter mit Gradientenabstieg so lernen, dass die Funktion das gewünschte Verhalten hat.
Im folgenden sehen wir uns die wesentlichen Modellierungsschritte im Detail an. Als erstes geht es darum, wie man ein Bild als input für das Netzwerk verwenden kann. Bisher war der input immer eine Zahl, so wie man es aus der Schule kennt. f(x) ist eine Funktion, und x nimmt bestimmte Zahlenwerte an, die man dann in die Funktion einsetzt um den Funktionswert zu berechnen. Wie geht das, wenn x ein Bild ist? In Abschnitt 3 wurde bereits angedeutet, dass man bei den „richtigen“ großen neuronalen Netzwerken mehrdimensionale Vektoren als input verwendet. Anstatt einer einzelnen Zahl steckt man gleich einen ganzen Vektor in die Funktion hinein. Das funktioniert grundsätzlich genau gleich, wie man es aus der Schule gewohnt ist. Eine einfache mehrdimensionale Funktion wäre beispielsweise
f(x)=3x1+sin(x1+x2)−x22, mit x=[x1,x2]∈R2
Statt einer einzelnen Zahl x hat man in der Funktion alle Komponenten xi des Vektors. Um ein Bild als input zu verwenden, nimmt man einfach alle Pixelwerte und macht daraus einen langen Vektor. Im vorliegenden Fall haben die input Bilder die Größe von 28×28 Pixel, d.h. der input Vektor hat 28⋅28=784 Dimensionen.
Der input Layer des MLP hat dementsprechend nun nicht mehr ein Neuron, sondern 784, für jede Komponente des input Vektor eines. Der hidden Layer hat nach wie vor eine frei wählbare Anzahl von Neuronen, aber jedes Neuron im hidden Layer bekommt nun den ganze 784-dimensionalen Vektor als input. Die Anzahl der Parameter für ein einzelnes Neuron ist d+1, d.h. ein einzelnes Neuron im hidden Layer hat nun schon 785 Parameter!
Für den output Layer wäre es verlockend, wieder ein einzelnes Neuron zu verwenden, sodass der output direkt die Zahl ist. Es hat sich aber gezeigt, dass man dem Netzwerk damit Ausdruckskraft nimmt. Daher verwendet man stattdessen einen überparametrisierten output: Anstatt einer einzelnen Zahl ist der output ein 10-dimensionaler Vektor. Am besten stellt man es sich so vor, dass der output Vektor eine Wahrscheinlichkeitsverteilung über alle 10 möglichen Ziffern ist. Das endgültige Ergebnis ist dann jene Zahl, die die höchste Wahrscheinlichkeit hat. Beispielsweise könnte der output Vektor lauten y=[0, 0, 0.3, 0, 0.6, 0, 0.1, 0, 0, 0], grafisch dargestellt:
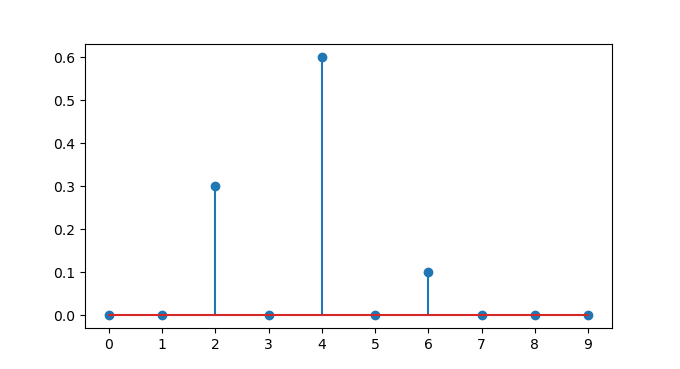
 [output-encoding-example.png]In Worten: die Ziffer 2 hat die Wahrscheinlichkeit 0.3, die 4 hat WS 0.6 und die 6 hat WS 0.1. In diesem Fall würde man als Ergebnis die Ziffer 4 nehmen, sie hat die höchste Wahrscheinlichkeit. Natürlich muss man nun die Trainingsdaten entsprechend anpassen, diese enthalten ja als Label nur die Zahl. Dazu wandelt man die jeweilige Zahl in den sogenannten one-hot Vektor um. Das ist ein Vektor, bei dem genau diejenige Komponente den Wert eins hat, die der Zahl entspricht, alle anderen sind 0. Für die Zahl 8 wäre der one-hot Vektor beispielsweise y=[0, 0, 0, 0, 0, 0, 0, 0, 1, 0], grafisch dargestellt:
[output-encoding-example.png]In Worten: die Ziffer 2 hat die Wahrscheinlichkeit 0.3, die 4 hat WS 0.6 und die 6 hat WS 0.1. In diesem Fall würde man als Ergebnis die Ziffer 4 nehmen, sie hat die höchste Wahrscheinlichkeit. Natürlich muss man nun die Trainingsdaten entsprechend anpassen, diese enthalten ja als Label nur die Zahl. Dazu wandelt man die jeweilige Zahl in den sogenannten one-hot Vektor um. Das ist ein Vektor, bei dem genau diejenige Komponente den Wert eins hat, die der Zahl entspricht, alle anderen sind 0. Für die Zahl 8 wäre der one-hot Vektor beispielsweise y=[0, 0, 0, 0, 0, 0, 0, 0, 1, 0], grafisch dargestellt:

Als letzte Änderung verwendet man nun auch im output layer eine Nichtlinearität. In dem Beispiel vorher haben wir die weggelassen, weil wir beliebige Funktionswerte als output ermöglichen wollten. Jetzt hat der output Vektor aber eine strukturelle Einschränkung: Die Werte sind alle zwischen 0 und 1, und damit es eine Wahrscheinlichkeitsverteilung ist sollen sich die 10 Konponenten zu 1 aufsummieren. Das erreicht man, indem man den Vektor durch die sogenannte softmax Funktion schickt. Die softmax funktion ist definiert als
softmax(x)=exp(xi)∑iexp(xi), x=[x1,x2,…,xn]∈Rn
wobei exp(⋅) die Exponentialfunktion ist. Der softmax „verstärkt“ quasi alle Komponenten xi mit der Exponentialfunktion, und normalisiert dann mit der Summe. Und weil die Verstärkung durch die Exponentialfunktion umso größer ist, je größer die Zahl die man hineinsteckt, dominiert der größte Wert alle anderen. Deshalb nennt man das ganze softmax, es ist eine Approximation an die Maximum-Funktion. Als netten Nebeneffekt erhält man auch noch, dass sich die Komponenten nach dem softmax auf 1 summieren, d.h. sie bilden eine Wahrscheinlichkeitsverteilung.
Das gesamte MLP sieht nun folgendermaßen aus:

Jede Einheit im input Layer nimmt eine Komponente des 784-dimensionalen input Vektor entgegen. Die Einheiten im hidden Layer, hier im Beispiel 6 Neuronen, bekommen jeweils den 784-dimensionalen input Vektor und berechnen damit ihre gewichtete Summe und die nichtlineare Aktivierungsfunktion. Die Neuronen im output layer bekommen jeweils einen 6-dimensionalen Vektor (jedes der 6 Neuronen im hidden layer erzeugt eine einzelne Zahl als output), und berechnen damit ihre gewichtete Summe. Der resultierende 10-dimensionale Vektor (weil es 10 Neuronen im output layer sind) geht in den softmax, und das ist dann der output Vektor y.
Das ganze MLP kann man wieder als Funktion f(x,p) betrachten, und diesmal gibt es eine ganze Menge Parameter! Wieviele es in diesem Beispiel mit 6 Neuronen im hidden Layer sind kann man ausrechnen: Die Neuronen im input Layer haben keine Parameter, sie führen keine Berechnung aus. Die Neuronen im hidden Layer haben jeweils d+1 Parameter, mit d=784. Es gibt 6 hidden Neuronen, das sind 4710 Parameter. Die Neuronen im output layer haben d=6, und es gibt 10 Neuronen, d.h. 70 Parameter im output Layer. Insgesamt hat das MLP 4780 Parameter.Wir können die Parameter mit zufälligen Werten initialisieren, und einmal beobachten was passiert wenn man ein paar input Bilder durch das Netzwerk schickt:

Hier sieht man 8 zufällig ausgewählte input Bilder, und darunter jeweils eine grafische Darstellung des output Vektors, den das Netzwerk ausrechnet. Da die Parameter zufällige Werte haben, berechnet das Netzwerk irgendeinen Datenmüll (wobei es im Fall der 7 in der zweiten Zeile sogar zufällig ein richtiges Ergebnis gibt).Die Aufgabe ist dieselbe wie ganz am Anfang: Passe die Parameter so an, dass der output dem gewünschten Ergebnis, d.h. in diesem Fall dem one-hot Vektor der die richtige Zahl kodiert, entspricht. Nur hat das Netzwerk jetzt immerhin 4780 Parameter an denen man drehen kann, das ist schon eine andere Dimension. Aber davon lässt sich der machine learning Engineer nicht abschrecken, sondern er minimiert die Loss Funktion mit Schema F: Gradient nach den Parametern ausrechnen und Gradientenabstieg ausführen. Tatsächlich ist das Ausrechnen des Gradienten – jetzt immerhin ein 4780-dimensionaler Vektor – nicht viel schwieriger als im Fall des einfachen MLP mit 7 Parametern, weil sich die Struktur oft wiederholt. Wenn man beispielsweise die Ableitung für das a1 in der linearen Transformation eines Neuron im hidden Layer ausgerechnet hat, dann sind die restlichen 783 Ableitungen für die a2,a3,…,a784 quasi auch schon fertig. Und für die übrigen Neuronen im hidden Layer ist es dann im wesentlichen nur mehr Kopierarbeit, weil die Ableitungen alle dieselbe Struktur haben. Man muss nur aufpassen, dass man den Datenfluss richtig abbildet. Deshalb sind solche schematischen Darstellungen wie in der Grafik oben äußerst nützlich, sie zeigen aus der Vogelperspektive wie die einzelnen Teile des MLP miteinander verbunden sind und welcher Vektor wohin geht.
Ich habe das ganze wieder in einem python notebook implementiert: https://colab.research.google.com/github/pingpong402/networks101/blob/main/network_mnist.ipynb In der Tat ist es fast dasselbe script wie zuvor, wo wir mit dem einfachen MLP die Funktion mit den 6 Punkten gelernt haben. Lediglich eine kleine Anpassung für den zusätzlichen softmax im output layer, und die Visualisierung ist jetzt ein bisschen aufwändiger. Aber der grundsätzliche Algorithmus sind dieselben paar Zeilen.
(Wer dieses script in der anonymen virtuellen Maschine laufen lassen möchte muss viel Geduld mitbringen. Man bekommt bei binder nur recht wenig Rechenleistung, das Service ist ja gratis. Die Optimierung läuft sehr langsam und es dauert lange. Es empfiehlt sich, dieses script in colab laufen zu lassen, da geht es recht flott.)

Auf der rechten Seite sind wieder 8 zufällige input Bilder sowie der aktuelle output während dem Lernen abgebildet. Man sieht sehr gut, wie die Parameter der Netzwerkfunktion angpeasst werden, sodass der output möglichst dem gewünschten one-hot Vektor entspricht. Manchmal dauert das ein bisschen: Bei dem Bild der 8 in der zweiten Zeil glaubt das Netzwerk zuerst eine Zeitlang es wäre eine 3, dann glaubt es kurz es wäre eine 5, und dann nach ca 140 Iterationsschritten sind die Parameter so angepasst, dass es korrekt die 8 erkennt. Manchmal funktioniert es auch gar nicht: Das Bild der 5 in der ersten Zeile wird bis zum Schluss nicht korrekt erkannt, dads Netzwerk glaubt nach wie vor es sei eine 1 (wobei diese 5 zugegebenermaßen recht schlampig geschrieben ist). Auf der linken Seite sieht man die Entwicklung des Loss sowie die Genauigkeit über alle Trainingdaten. Ich habe hier „nur“ 20.000 der 70.000 Trainingsbeispiele verwendet, damit die Sache ein bisschen schneller geht. Damit erreicht das MLP mit 6 hidden Neuronen eine Genauigkeit von 88%, d.h. 88% der 20.000 Bilder werden richtig erkannt. Nicht schlecht für ein Netzwerk mit knapp 5000 Parametern!Natürlich machen wir jetzt das Netzwerk wieder mächtiger, indem wir mehr hidden Neuronen verwenden. Hier ist das Ergebnis mit 30 Einheiten im hidden Layer, das MLP hat dann knapp 24.000 Parameter und erreicht eine Genauigkeit von 95%:

Ich habe den Gradientenabstieg nach 400 Iterationsschritten (dauert ca. 10 Minuten) abgebrochen, aber man sieht, dass die Optimierung noch nicht konvergiert ist. Die Loss-Kurve sinkt weiterhin, und vermutlich hätte das MLP eine noch höhere Genauigkeit erreicht wenn man noch weiter trainiert hätte. Man kann gerne in dem script herumspielen und zB einmal richtig lange trainieren, vielleicht 2000 Iterationen oder so, um zu sehen wie hoch man mit der Genauigkeit kommt. Fortgeschrittene können das script auch verwenden um mit eigenen Trainingsdaten andere Probleme zu lösen. Alles was man tun muss ist die Variablen X (input Daten) und Y (gewünschter output) mit seinen eigenen Daten zu ersetzen (X und Y sind numpy Arrays, jede Spalte ist ein Trainingsbeispiel).
4. Fazit
Machine Learning und künstliche neuronale Netze sind keine Hexerei. Es ist im Prinzip angewandte lineare Algebra und Analysis. Einer der Grundpfeiler, auf dem das ganze Gebiet ruht, ist die Optimierung mit Gradientenabstieg. Weiters braucht man jede Menge Trainingsdaten und Rechenleistung, die großen modernen neuronalen Netze haben viele Milliarden Parameter. Um noch einmal auf das Bild von ganz zu Beginn zurück zu kommen: Es sind mathematische Boxen mit input, output und vielen Milliarden Drehreglern. Das Training besteht darin, die Drehregler so anzupassen, dass die Funktion das tut was man will, d.h. wie es durch die Trainingsbeispiele vorgegeben ist. Gut, dass diese aufwändige Arbeit der Computer macht 🙂
Disclaimer: Beim Schreiben dieses Textes wurde keine KI verwendet. Die Bilder wurden teilweise mit Gemini erzeugt.
Gefällt mir Wird geladen …
